Comparative Effectiveness of Machine Learning Methods for Causal Inference
Abstract
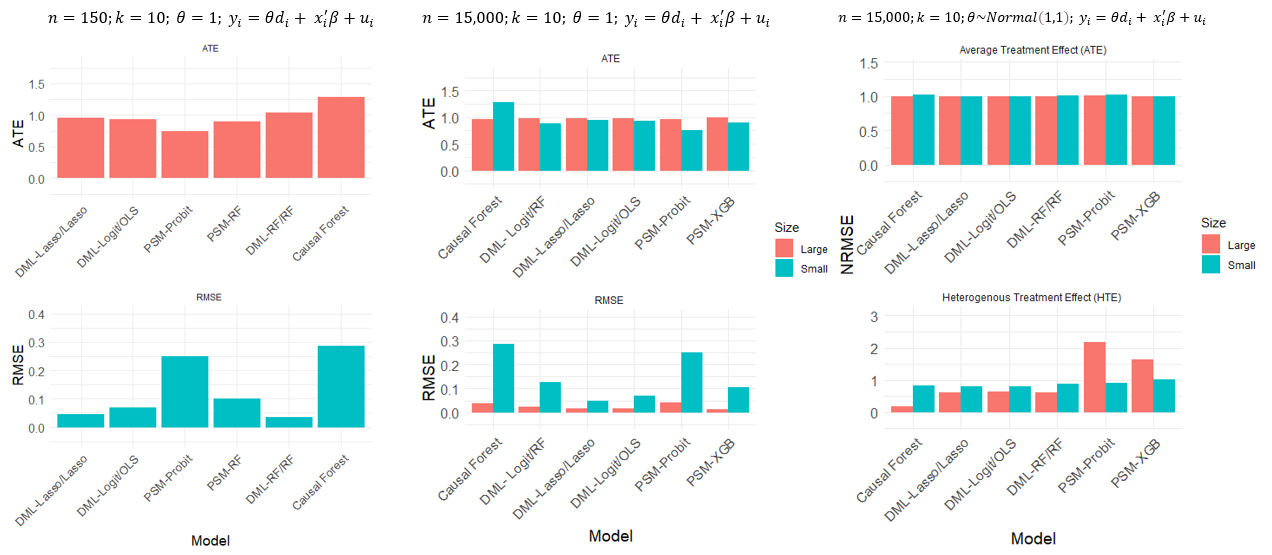
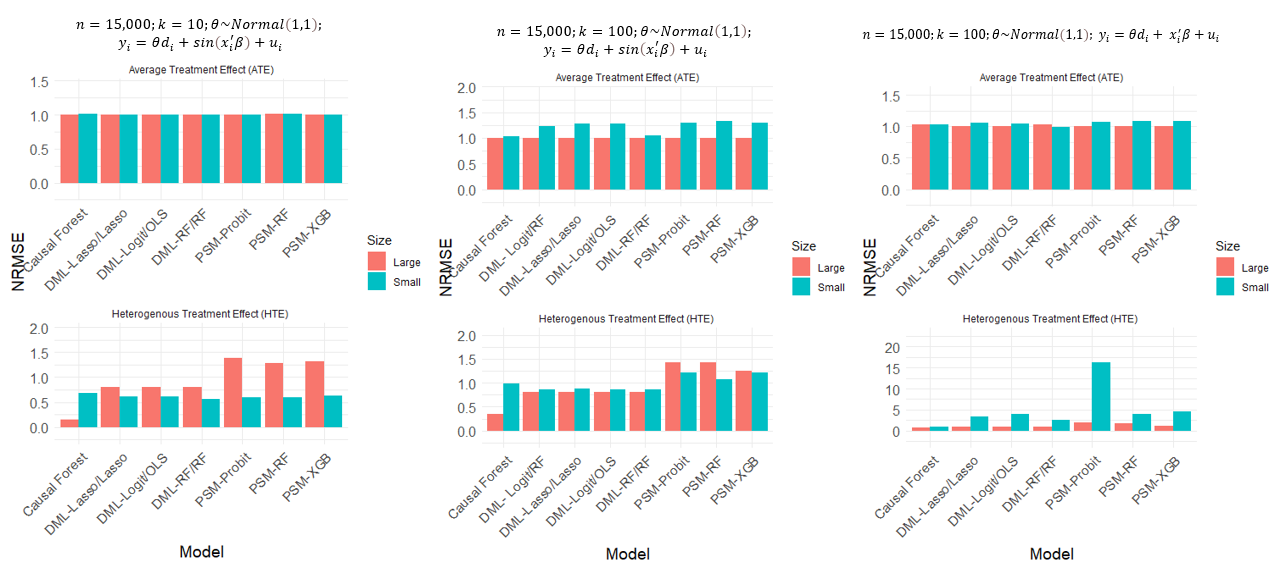
We compare three causal machine learning (ML) methods: causal forest (CF), double ML (DML), and propensity score matching with ML (PSM-ML) across various treatment effects, model complexities, data dimensions, and sample sizes. The simulation study reveals that CF performs well for heterogeneous treatment effects but needs a larger sample size; PSM fairly performs in simple cases when treatment effects are homogeneous, but DML outperforms these two in most other cases. Applying these models to two experimental studies, we find that the choice of model can greatly affect the statistical significance of causal estimates, such as Lasso-based DML revealing significant weight loss from skipping breakfast, which a prior study using traditional methods found insignificant. Our results highlight the need to consider various flexible approaches to answer causal questions.